Scanner-Induced Domain Shifts Undermine the Robustness of Pathology Foundation Models
Abstract
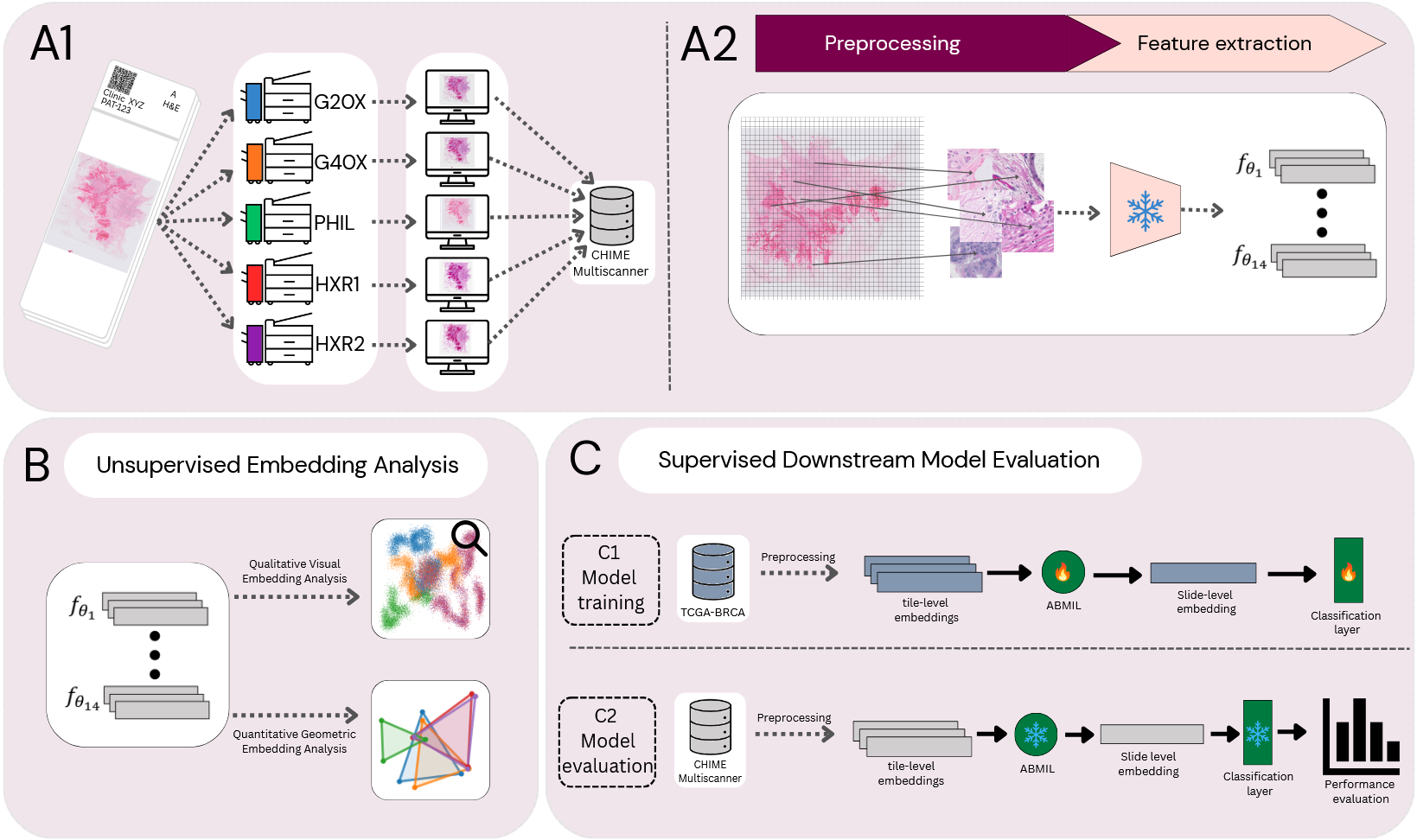
Pathology foundation models (PFMs) have become a central building block for computational pathology, aiming to provide a general encoder enabling feature extraction from whole-slide images (WSIs) for a wide range of downstream prediction tasks. Despite strong reported performance in benchmark studies, the robustness of PFMs to technical domain shifts commonly encountered in real-world clinical deployment and across studies remains poorly understood. In particular, variability introduced by differences in whole-slide scanner devices represents a common source of variability that has not been characterised as a primary source of domain shift. In this study, we systematically evaluated the robustness of 14 PFMs to scanner-induced variability. The evaluated models include state-of-the-art PFMs, earlier pathology-specific models trained with self-supervised learning, and a ResNet baseline model trained on natural images. Using a controlled multiscanner dataset comprising 384 breast cancer WSIs scanned on five different whole-slide scanners, we isolate scanner effects independently of biological and laboratory confounders. Robustness is assessed through complementary unsupervised analyses of the embedding space and a set of clinicopathological supervised prediction tasks, including histological grade and routine biomarker predictions from hematoxylin and eosin images. Our results demonstrate that current state-of-the-art PFMs are not invariant to scanner-induced domain shifts. Most models encode pronounced scanner-specific variability in their embedding spaces, leading to substantial distortions in both global and local feature space across scanners. Although prediction performance largely remains similar when measured by AUC, this apparent robustness masks a critical failure mode: scanner variability systematically alters the embedding space and impacts calibration of downstream model predictions, resulting in scanner-dependent bias that can impact reliability in, for example, clinical use cases. We further show that robustness to scanner variability is not a simple function of training data scale, model size, or model recency. None of the models provided reliable robustness against scanner-induced variability. The models trained on the most diverse data, here represented by vision-language models, appear to have an advantage with respect to robustness, while these models did not perform among the top models in the performance evaluation on supervised tasks. We conclude that development and evaluation of PFMs requires moving beyond accuracy-centric benchmarks toward explicit evaluation and optimisation of embedding stability and calibration under realistic acquisition variability.