Semantic Self-Distillation for Language Model Uncertainty
Abstract
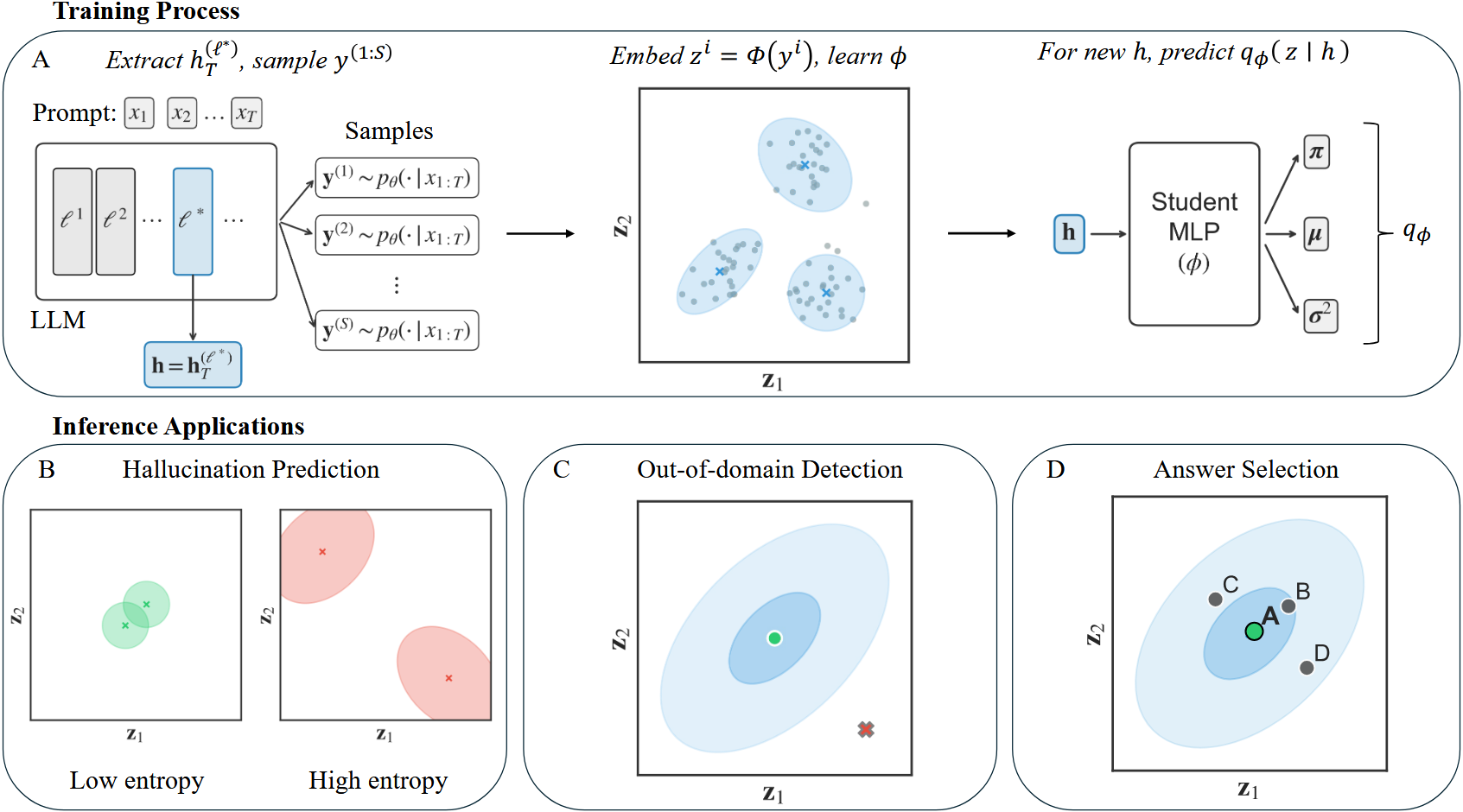
Large language models present challenges for principled uncertainty quantification, in part due to their complexity and the diversity of their outputs. Semantic dispersion, or the variance in the meaning of sampled answers, has been proposed as a useful proxy for model uncertainty, but the associated computational cost prohibits its use in latency-critical applications. We show that sampled semantic distributions can be distilled into lightweight student models which estimate a prompt-conditioned density before the language model generates an answer token. The student model predicts a semantic distribution over possible answers; the entropy of this distribution provides a prompt-level uncertainty signal, and the probability density allows answer-level reliability evaluation. Across experiments on TriviaQA and MMLU, we find our student models perform competitively relative to sampling-based semantic dispersion baselines on a hallucination prediction task, whilst offering additional uncertainty primitives for out-of-domain detection and multiple-choice answer selection. We term this technique Semantic Self-Distillation (SSD), which can serve as a general framework for distilling predictive uncertainty in complex output spaces beyond language.