Entropy Alone is Insufficient for Safe Selective Prediction in LLMs
Abstract
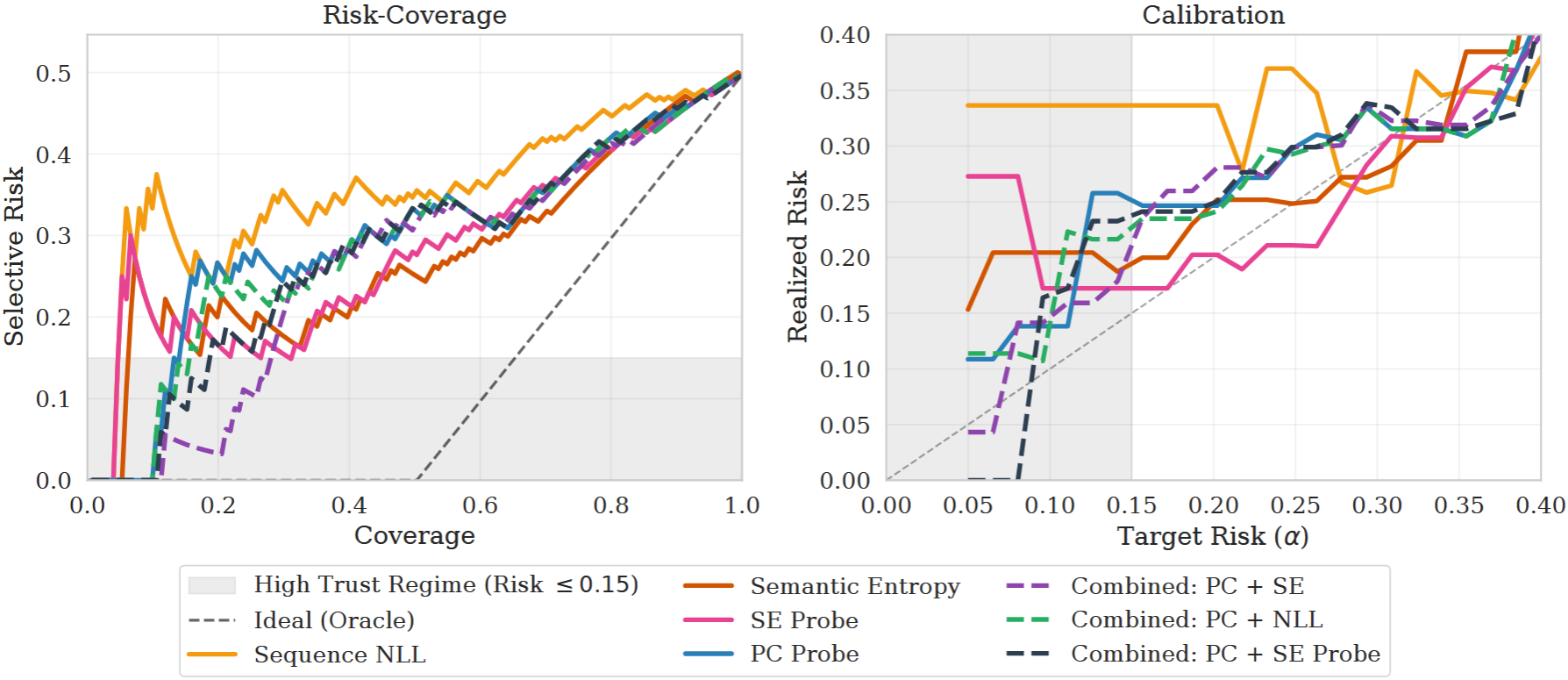
Selective prediction systems can mitigate harms resulting from language model hallucinations by abstaining from answering in high-risk cases. Uncertainty quantification techniques are often employed to identify such cases, but are rarely evaluated in the context of the wider selective prediction policy and its ability to operate at low target error rates. We identify a model-dependent failure mode of entropy-based uncertainty methods that leads to unreliable abstention behaviour, and address it by combining entropy scores with a correctness probe signal. We find that across three QA benchmarks (TriviaQA, BioASQ, MedicalQA) and four model families, the combined score generally improves both the risk–coverage trade-off and calibration performance relative to entropy-only baselines. Our results highlight the importance of deployment-facing evaluation of uncertainty methods, using metrics that directly reflect whether a system can be trusted to operate at a stated risk level.